Introduction
There are two kinds of datasets. One dataset displays ratings provided by users to movies. Every user is represented by a unique user ID, and each movie has a unique ID. The other dataset provides movie description viz. title and genre. There are multiple ratings for each movie and many ratings associated with every user. The dataset is a record of ratings given by a user to all the watched movies and a record of ratings given by a set of users to a movie. The aim of data analysis is to build a personalised set of recommendations for every user by carefully analysing user preferences for movies of different genres, based on individual user ratings. The recommended set has movies never watched by a user. The target user may be a new user or a user with a movie watch history.
A section of ratings data and movies data is shown:
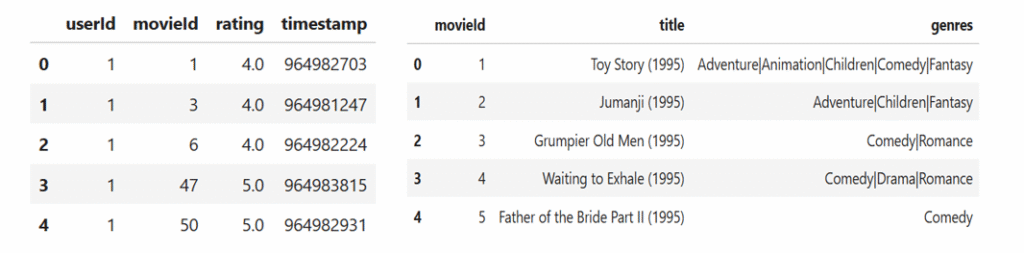
The movies can be selected by filtering movies watched by the most similar users or filtering movies very similar to the movies highly rated by the target user. Hence, the recommendation system can be user-based or item-based. There are primarily three types of recommendation systems: collaborative filtering based on user-user similarity, collaborative filtering based on item-item similarity, system based on content similarity.
Data pre-processing
The datasets are checked for null values. Next, the data sets are checked for any duplicate entries. The duplicate entries are identified by dropping values similar in user ID, movie ID and rating or values similar in the combination of movie ID, movie title and genres. The data ratings can be normalised in the fixed range (0,1). For content-based movie recommendation system, the movie genres are identified and each genre is added as a separate column to the movie data. The genre columns are filled with binary values of 0 and 1. The binary values in a row indicate all those genre categories a specific movie belongs to. The ratings and movie data are merged by using movie ID as a common column.
Exploratory Data Analysis
Figure 1 shows the rating distribution.
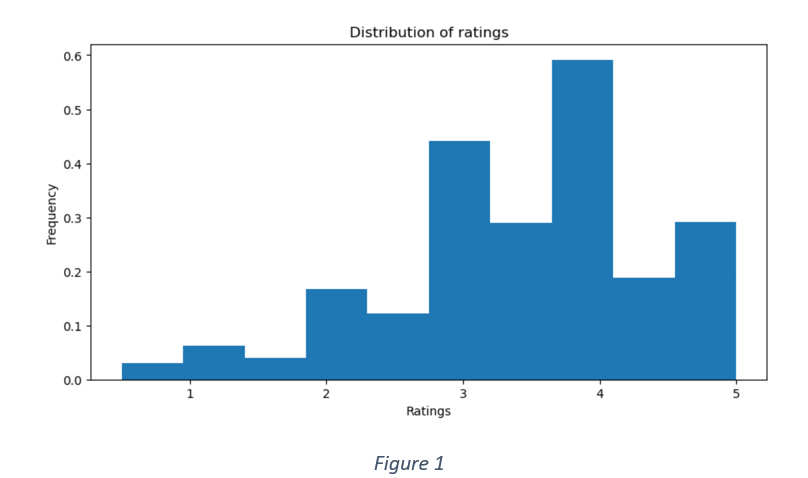
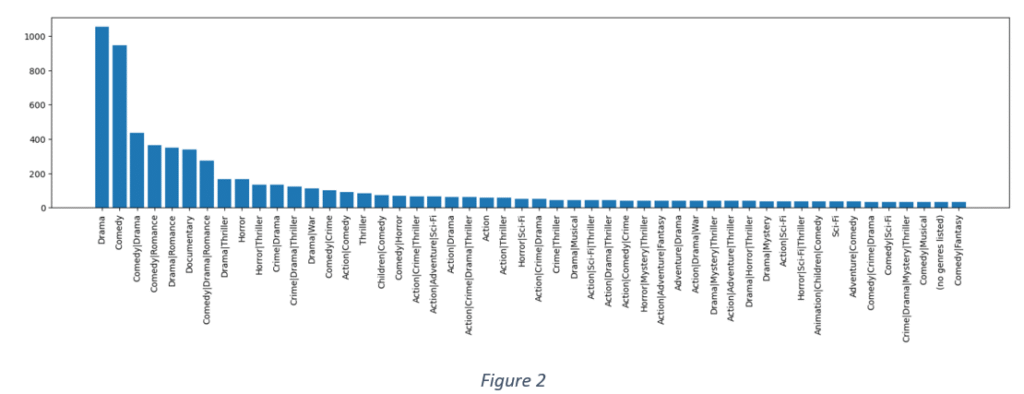
It is observed that the highest frequency of ratings is in the range (3,4). A distribution of genres in Figure 2 indicates that drama and comedy have the highest frequency count.
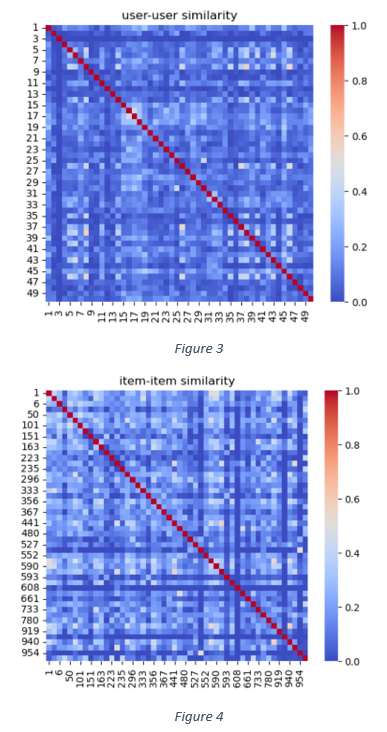
The user-user correlation matrix (Figure 3) shows the similarity of the maximum number of user pairs is less than 0.4. Similarly, item-item heat map in Figure 4 shows the similarity of many item pairs is less than 05.
The rating data and movies data are combined and the merged data is reorganised into user-item interaction matrix, as shown in Table 2.
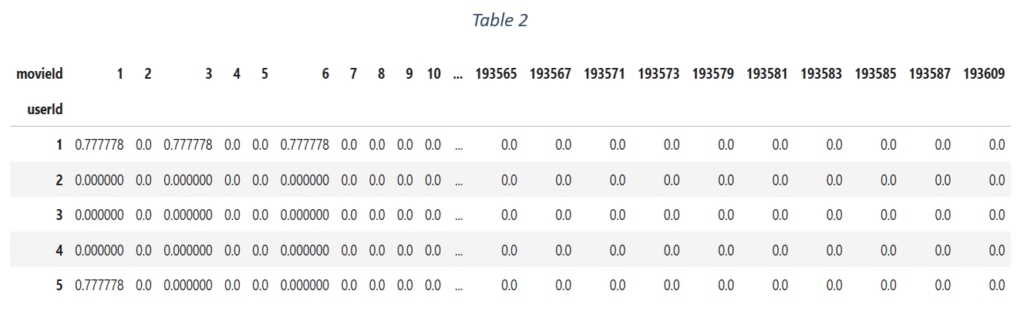
The rows represent user IDs and columns represent movie IDs. Each intersection of user ID and movie ID is the rating given by the user to the corresponding movie.
User based collaborative filtering
In user based collaborative filtering, user-user similarity matrix is created from user-item interaction matrix, as shown in Table 3.
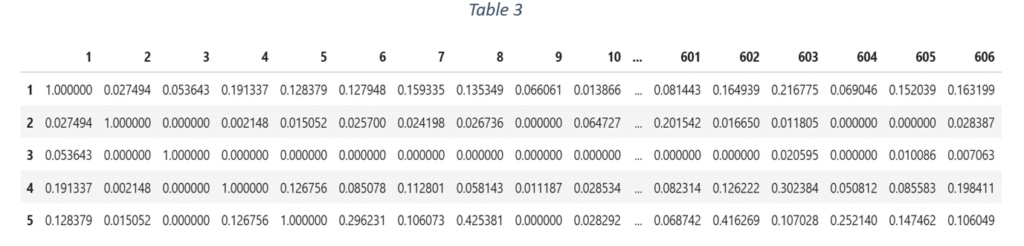
The user similarity is based on similarity in ratings given by a pair of users. The similarity matrix is further used to identify the most similar users for a target user. The threshold for selecting the most similar users is 0.8. Next, the set of movies watched by the most similar users is filtered. For each movie in the set, the average rating is calculated. The movies are arranged in the decreasing order of average rating. The movies with average rating more than 0.8 and never watched by target user are filtered as a set of recommended movies. Table 4 shows the list of movies with average predicted ratings more than 0.8 for target user ID ‘23’.
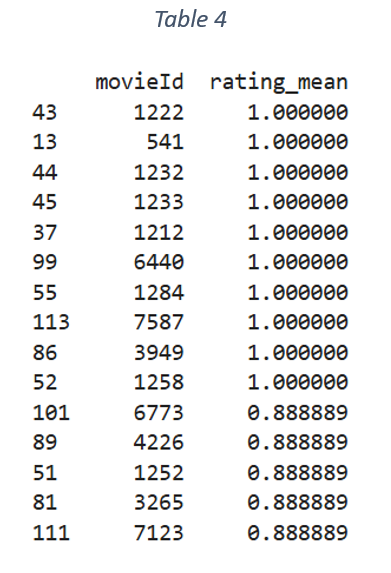
Below is the list of movies extracted from Table 4 that were never watched by the target user.

The robustness of recommendation system is tested by calculating Root mean square error, Precision at K and Recall at K.
Root Mean Square Error (RMSE): The average of ratings watched by the most similar users is the predicted rating for each movie. The predicted ratings and actual ratings of all those movies watched by the target user are extracted. Root mean squared error is computed from the mean squared difference of predicted and actual rating.
Precision at K is calculated by computing the ratio of number of movies in the recommended list that are relevant for target user to the total number of movies in recommended list. The relevant movies are the movies watched and rated very highly by the target user.
Recall at K is the ratio of number of relevant movies in the recommended list to the total number of movies relevant for the target user.
Item based collaborative filtering
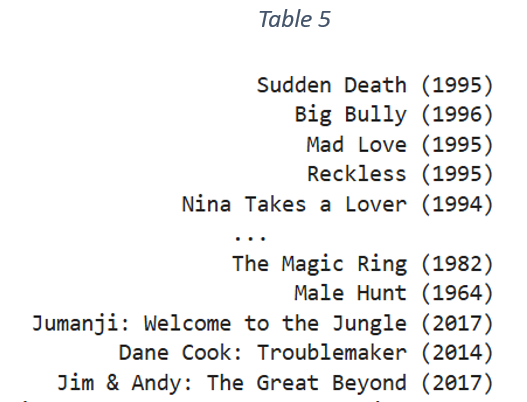
In item based collaborative filtering, item-item similarity matrix is generated. The similarity is based on the number of common users and similarity in their respective ratings. The matrix is used to identify movies highly similar to the movies watched and rated very highly by the target user. The identified movies are selected as the list of recommended movies for the target user. The metrics to assess the performance of the recommended list are precision and recall. Table 5 is the list of a subset of movies from the recommended list for user ID ‘23’.
Content based collaborative filtering
The execution of content-based filtering is similar to item-based recommendation system. The only difference lies in calculation of content similarity of a pair of movies. The degree of similarity is based on number of common genres/categories between the two movies. The similarity matrix is used to identify movies highly similar to the movies watched and rated very highly by the target user. The identified movies are selected as the list of recommended movies for the target user. Table 6 is the list of a subset of movies from the recommended list for user ID ‘23’.
Hybrid recommendation system
There are different ways of creating a hybrid recommendation system. A hybrid system can be created by stacking the lists of movies from user based, item based and content-based recommendation system. Another is the cascading approach where the recommended movies from user and item-based filtering are combined. The combined list is further used to select movies similar in content to the movies and highly rated by the target user. The resultant list is a smaller subset of recommended movies. Table 7 shows the recommended movies from cascading model and stacking model.
SVD based approach
Singular Value Decomposition (SVD) is used to decompose a matrix into a set of three matrices. The user-item matrix is decomposed into a set of three matrices; User matrix, Item matrix and a third matrix representing the strength of each latent feature. In user matrix, each row is a user and each column represents a dimension or a latent feature. In item matrix, each row is an item and each column is a latent feature. The idea behind implementing SVD in recommendation system is to improve the accuracy of estimated values of user-item matrix by lowering the error difference between actual rating and predicted ratings. The predicted ratings are obtained from the dot product of user matrix and item matrix components of the user-item matrix. The user and item matrices are continuously improved by training the SVD model. The trained model is evaluated on the test sample of user IDs, item IDs and ratings. The model can be used to predict the rating for a combination of user ID and movie ID.
For a target user ID, a dictionary of movie IDs and estimated ratings is created. The movie IDs with predictions more than 0.8 are extracted and recommended for the target user. Table 8 shows the recommended list from SVD model.

Final list of recommendations
Exceptions: The thresholds set for user-user similarity, item-item similarity or highly rated movies are likely to influence the outcomes of the recommendation systems. A high threshold may not satisfy the similarity condition, thereby generating empty lists of very similar users or items. Consequently, the recommended list is an empty list. Such exceptional cases are acknowledged by declaring performance metrics as ‘non-applicable’.
Comparison of recommendation systems
Table shows the performance metrics of all the recommendation systems.
Pros and cons of different recommendation systems
User based collaborative filtering: Is quite useful when a user has a watch history and shares similar interests with many other users. However, the method is not feasible for a new user or for a user whose preferences do not match with those of the other users.
Item based collaborative filtering: Is implemented when an item has already been used by many users. Therefore, it is easy to extract similar items based on the number of common users and similar ratings given by the same users. Item based collaborative filtering cannot be used for a new item. In such cases, the content or the item features should be analysed to find the most similar items and the users who rated them highly. Item based is also not effective if item-item similarity is low.
Content based filtering approach: Content based approach is useful in addressing the cold start problem where either the user or item is new. The new user can be recommended items based on one’s preferences in features/genre that the user selected for the first time. It helps offer a more personalised service to the users. Similarly, a new item can be offered to the existing users whose preferences match with the item features.
Hybrid model (cascading approach): In one hybrid approach, the recommended items from collaborative filtering were passed through content-based filtering to find more items similar in content/features. The idea behind this approach is to offer more choices to the target user. The underlying assumption of this approach is that the user or the item is not new and shares similarity with many other users or items based on the usage history. It is also assumed that collaborative filtering will generate a list of movies in alignment with the user interests.
Hybrid model (stacking approach): In this approach, the recommended items from both collaborative and content-based filtering are combined. Here, an equal weightage is given to both the approaches and all the top recommended movies are selected from all methods. This method can also generate results for a cold start problem where content-based approach alone can recommend movies to a new user.
Evaluation metrics:
Precision at K: It is used to find the ratio of relevant items from the recommended list to the number of recommended items. The evaluation metric can be used to test a recommendation system only when a user actually watches a movie from the recommended list and gives it a high rating. Higher the precision, more robust the recommendation system. However, precision is not an effective metric if a user has watched and rated very few movies from the recommended list. It is difficult to assess the robustness in case of low precision, as the user’s opinions about most of the other movies is not known.
Recall at K: Is a useful metric in determining if the recommended list offers only relevant items to the target user.
RMSE: The metric is useful only when the actual user ratings are known and there is a high similarity between a target user and its similar users. In case of low user-user similarity, the predicted movie ratings will not be a good estimate of the actual ratings. RMSE also cannot be used for a new user.